I’ve been diving deep into the world of AI and machine learning lately, and one technology that keeps popping up everywhere is vector databases. At first, I’ll admit, the concept seemed pretty abstract and technical. But once I understood what they actually do and why they matter, everything clicked. So let me break it down for you in the simplest way I can.
The Problem Vector Databases Solve
Think about how traditional databases work. You store data in rows and columns, and when you want to find something, you search for exact matches or use filters. If I’m looking for a customer named “John Smith,” the database finds exactly that name. Simple, right?
But here’s where it gets interesting. What if you want to find things that are similar but not identical? What if you’re building an AI application that needs to understand meaning, context, and relationships between data? Traditional databases aren’t built for that.
That’s where vector databases come in.
What Exactly is a Vector Database?
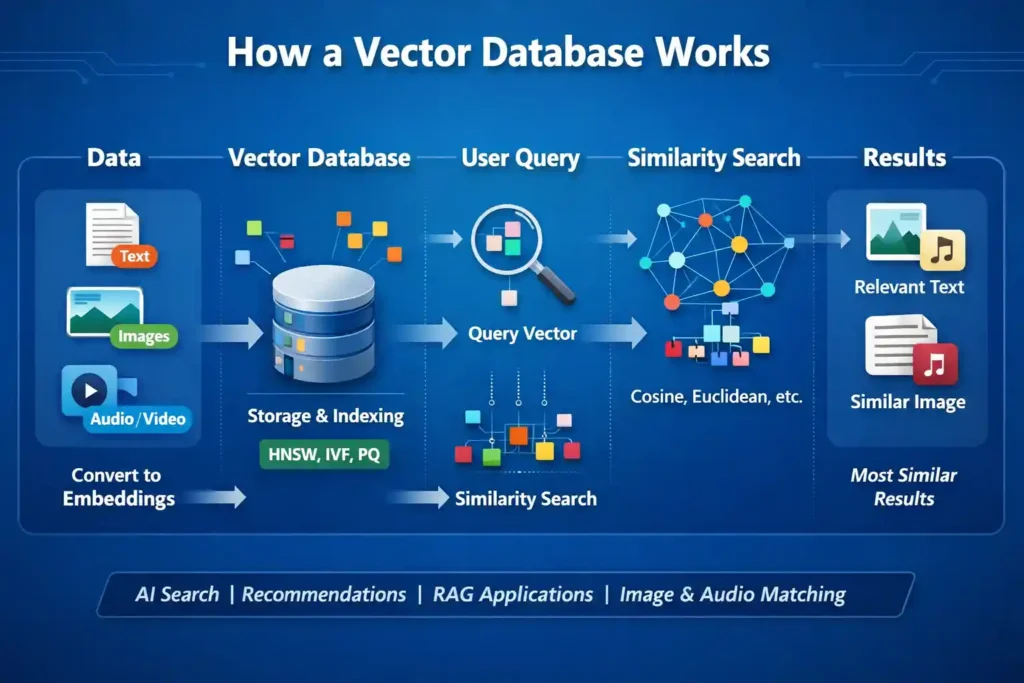
A vector database is a specialized type of database designed to store and search through high-dimensional vectors. Now, I know “high-dimensional vectors” sounds intimidating, but stick with me.
A vector is essentially just a list of numbers that represents something. Think of it as coordinates in space, but instead of just X and Y (like on a map), you might have hundreds or even thousands of dimensions. These numbers capture the “essence” or “meaning” of data.
For example, the word “dog” might be represented as a vector like [0.2, -0.5, 0.8, 0.1, …] with hundreds of numbers. The word “puppy” would have a similar but slightly different vector because the meanings are related.
How Does It Actually Work?
Let me walk you through the process:
Step 1: Converting Data into Vectors
First, you need to transform your data into these numerical vectors. This is done using something called an embedding model. Whether it’s text, images, audio, or even video, the embedding model converts it into a vector that captures its semantic meaning.
I like to think of this as translating everything into a universal language that computers can understand and compare.
Step 2: Storing the Vectors
Once you have these vectors, they’re stored in the vector database along with any associated metadata (like the original text, IDs, timestamps, whatever you need). The database organizes these vectors in a way that makes searching through millions of them incredibly fast.
Step 3: Similarity Search
Here’s where the magic happens. When you want to find something, you convert your query into a vector using the same embedding model. Then the database finds the vectors that are closest to your query vector in that high-dimensional space.
The “closeness” is measured using mathematical distance metrics like cosine similarity or Euclidean distance. Vectors that are close together represent semantically similar things.
Why This Matters for AI Applications
I’ve seen vector databases become essential for modern AI applications. Here’s why:
Semantic Search: Instead of just matching keywords, you can search based on meaning. If someone searches for “happy puppy,” they might get results about “joyful dogs” even though the exact words don’t match.
Recommendation Systems: Vector databases can find similar products, movies, or content based on what users have liked before. Netflix and Spotify rely heavily on this kind of technology.
RAG (Retrieval Augmented Generation): This is huge for AI chatbots and assistants. When you ask a question, the system uses a vector database to quickly find relevant information from a knowledge base, then feeds that to a language model to generate an accurate answer.
Image and Face Recognition: Finding similar images or identifying faces works brilliantly with vector databases because visual features can be captured as vectors.
Popular Vector Databases
If you’re thinking about using one, here are some options I’ve come across:
- Pinecone: Fully managed, easy to use, great for getting started quickly
- Weaviate: Open-source with strong GraphQL support
- Milvus: Open-source and highly scalable for large deployments
- Chroma: Lightweight and perfect for local development
- Qdrant: Fast and has excellent filtering capabilities
The Bottom Line
Vector databases aren’t just another database trend. They’re solving a fundamental problem in how we search and understand unstructured data. As AI continues to evolve, the ability to quickly find semantically similar information becomes more and more critical.
For me, understanding vector databases opened up a whole new way of thinking about data. Instead of exact matches and rigid schemas, we’re now working with meaning and context. And honestly? That’s pretty exciting.
If you’re building anything with AI, especially if it involves search, recommendations, or working with large language models, I’d definitely recommend getting familiar with vector databases. They’re becoming as fundamental to AI applications as traditional databases are to web applications.