Ordinary Least Squares
Most likely, you have previously encountered a trendline on a scatter plot. Through a cloud of dots, that straight line? It was unable to…
Read articleArchive
Most likely, you have previously encountered a trendline on a scatter plot. Through a cloud of dots, that straight line? It was unable to…
Read article
If you’ve ever wished you had a brilliant coding teammate available who knows your entire codebase inside and out, Claude Code might be exactly…
Read article
We’ve built AI for the U.S. military, and we’re proud of it. But the Pentagon is now asking us to remove safeguards we believe…
Read article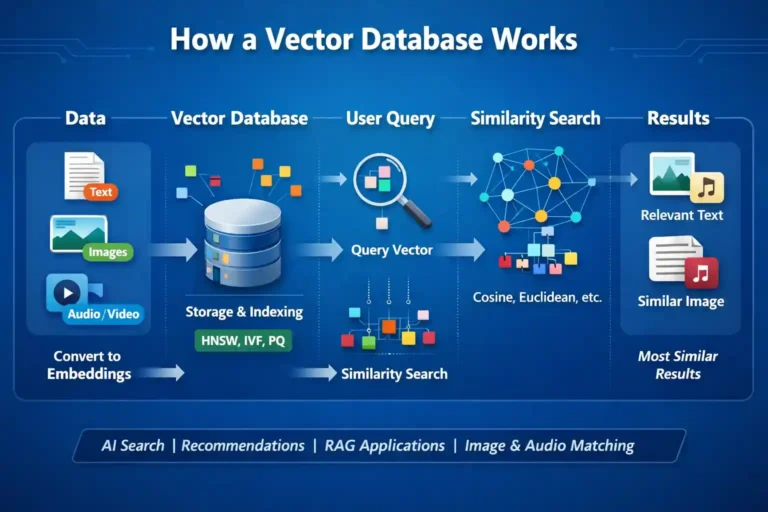
I’ve been diving deep into the world of AI and machine learning lately, and one technology that keeps popping up everywhere is vector databases.…
Read article
Data Science and Artificial Intelligence are among the most in-demand skills today. Many top Indian institutes now offer online programs that allow students and…
Read article
Are you usually confused about the difference between deep learning and machine learning? You’re not alone! These terms are frequently used interchangeably, but they…
Read article