Ordinary Least Squares
Most likely, you have previously encountered a trendline on a scatter plot. Through a cloud of dots, that straight line? It was unable to…
Read articleInsights
Most likely, you have previously encountered a trendline on a scatter plot. Through a cloud of dots, that straight line? It was unable to…
Read articleImagine you’re a restaurant owner. You notice that on warmer days, more people buy ice cream. If you could quantify that relationship, you could…
Read article
I have shared basic to advanced-level interview questions and answers. BASIC LEVEL (1-20) 1. Reverse a String 2. Check if a string is a…
Read article
I was wondering, every time I learned a data science course, I saw R. But today I learned about it, and I will give…
Read article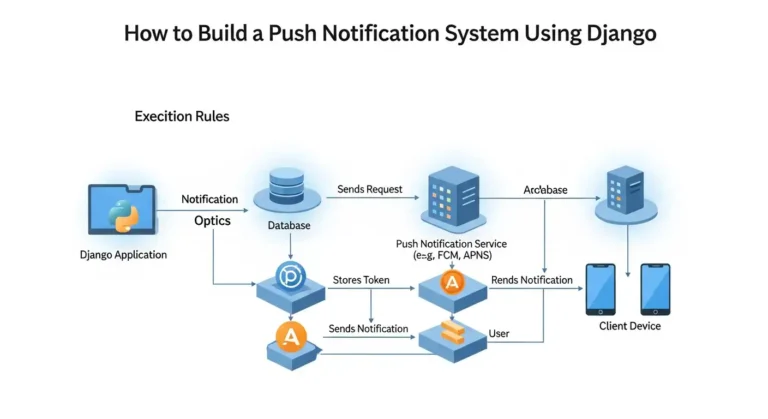
Imagine your app could send instant updates to users the moment something important happens, whether it’s a new message, an order update, or a…
Read article
If you’ve ever wished you had a brilliant coding teammate available who knows your entire codebase inside and out, Claude Code might be exactly…
Read article
We’ve built AI for the U.S. military, and we’re proud of it. But the Pentagon is now asking us to remove safeguards we believe…
Read article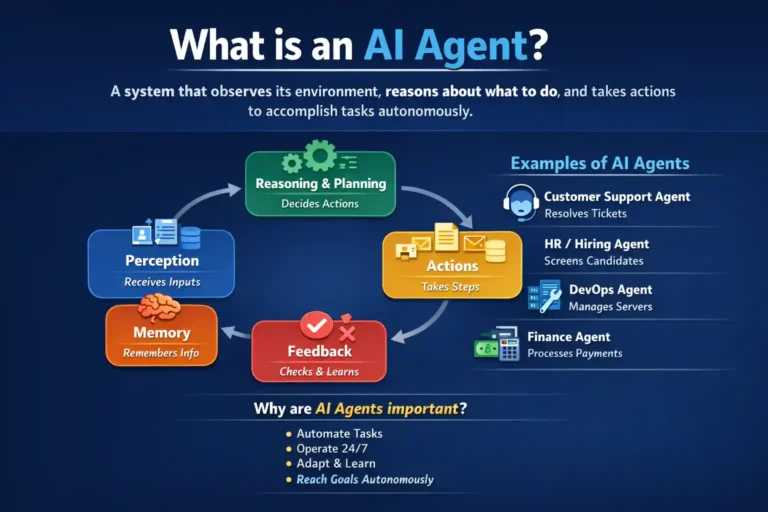
In this blog, I’ll provide a short and clear explanation of how you can create your own AI agent.I’ll walk you through a comprehensive…
Read article
Hallucination (General): Experiencing things that aren’t really there, seeing, hearing, or feeling something that doesn’t exist in reality. Your brain creates sensory experiences without…
Read article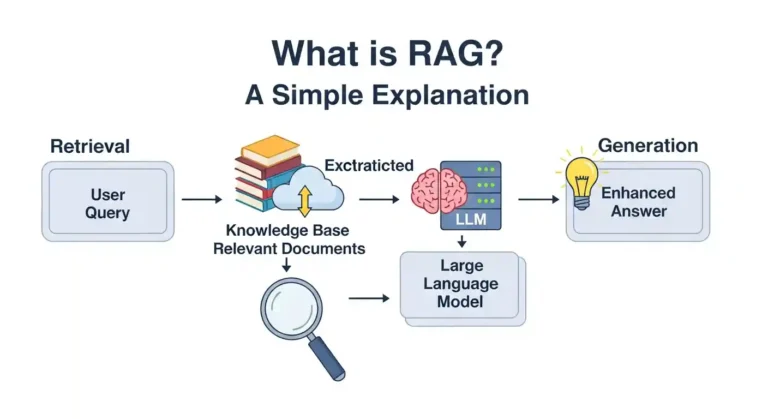
So you’ve undoubtedly heard the term “RAG” thrown around in AI chats and are wondering what it means. Don’t worry, it’s not as complicated as it seems, and I’ll explain it in plain English. The Basics RAG stands for Retrieval-Augmented Generation. I know that sounds super technical. But here’s the thing: it’s actually a pretty clever…
Read article