Simple 5-Step Roadmap to Build Your Own Generative AI
If you want to build your own AI? Not just use ChatGPT, but actually create one? I’ve been there, and let me tell you,…
Read articleArchive
If you want to build your own AI? Not just use ChatGPT, but actually create one? I’ve been there, and let me tell you,…
Read article
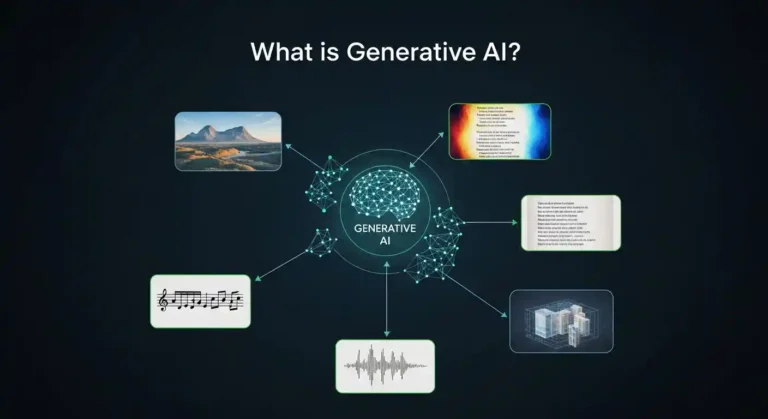
In this articlal i will give a brief explanation of what generative AI is and has quickly become one of the most essential technological…
Read article
Very few know how to build a SaaS platform that safely serves hundreds or thousands of companies from a single system. The difference is…
Read article
Learning Python by building games is one of the most effective ways to develop real programming skills. Each game teaches specific concepts while keeping…
Read article
So I’ve been wanting to build my own blog for a while now, and after trying out a bunch of different platforms like WordPress…
Read article
SQL (Structured Query Language) remains one of the most in-demand skills for data analysts, database administrators, and backend developers. Whether you’re preparing for your…
Read article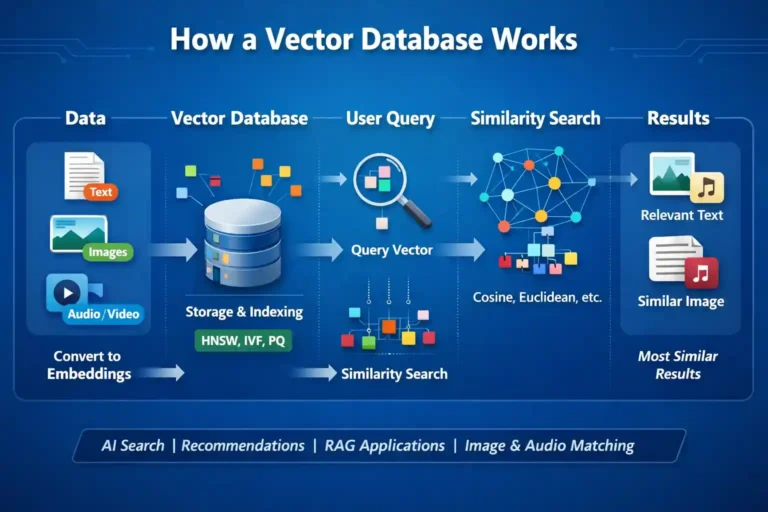
I’ve been diving deep into the world of AI and machine learning lately, and one technology that keeps popping up everywhere is vector databases.…
Read article
The Python job market has changed—and fast. Companies don’t care how many certificates you’ve collected. They care about one thing only: can you build…
Read article
I recently built a Netflix clone without writing most of the code myself. Before you close this tab thinking I’m advocating for replacing human…
Read article
Let me tell you something—I’ve wasted countless hours building dashboards from scratch, wrestling with JavaScript frameworks, and questioning my life choices. Then I discovered…
Read article